ОКОГУ по ИНН | Как узнать ОКОГУ для ООО и ИП по ИНН онлайн? — Контур.Бухгалтерия
Для систематизации и учета информации о хозяйствующих субъектах государство сформировало классификаторы. Они упрощают обработку данных, присваивая коды предприятиям. Один из классификаторов — ОКОГУ. В статье расскажем, что такое ОКОГУ, для чего он нужен, и как его получить.
Что такое ОКОГУ
ОКОГУ — это общероссийский классификатор органов государственной власти и управления. Классификатор включает коды всех органов госвласти. Коды ОКОГУ нужны для идентификации государственных органов, но это не значит, что ИП и юрлица не могут его получить. Они присваиваются организациям, по которым ведется статистическое наблюдение. ОКОГУ присваивается:
- федеральным госорганам;
- муниципальным органам;
- органам самоуправления на местах и избирательным комиссиям;
- субъектам хозяйствования, которые являются объектами статистического наблюдения;
- межгосударственным органам управления.

Зачем нужен ОКОГУ
На государственном уровне органы власти — такие же субъекты, как и организации, и их тоже нужно контролировать. Классификатор ОКОГУ помогает упорядочить и систематизировать информацию об органах управления и упрощает понимание подчиненности и ответственности властных структур.
Как и другие организации, зарегистрированные в налоговой, органы власти включаются в единый госреестр. С помощью ОКОГУ их легко идентифицировать и проще вести статистический учет.
Структура ОКОГУ
Структура классификатора имеет иерархический характер, то есть отражает порядок подчинения органов управления. Подчиненность определяется на основании Конституции, федеральных законов и Указа Президента «О структуре органов исполнительной власти». Код включает 7 знаков, первый из них зависит от объекта кодирования. Выделяют 5 групп объектов:
Органы госвласти:
- Президент, законодательная, исполнительная и судебная власть РФ. Другие федеральные органы и Центробанк.
- Органы госвласти регионов.
- Органы местного самоуправления.
- Предприятия и организации, по которым ведется статистическое наблюдение (банки, академии, фонды, госкорпорации). Группировки хозсубъектов и общественных объединений, необходимые для статистического учета.
- Межгосударственные органы управления.

Для нас интересны коды из 4 группы, а именно группировки хозсубъектов. Большинству организаций присваивается код 4210014, ИП — 4210015. Росстат отвечает за ведение и разработку изменения для ОКОГУ. Все проекты изменений, предварительно вносятся на рассмотрение в Росстандарт.
Как узнать свой ОКОГУ для ООО и ИП
Коды статистики нужны при внесении изменений в учредительные документы, смене руководителя, открытии филиала или по запросу требовательных контрагентов. Также уведомления с кодами из Росстата нужны для получения допусков и разрешений.
Статистические коды должны выдаваться в форме письменного уведомления при регистрации предприятия.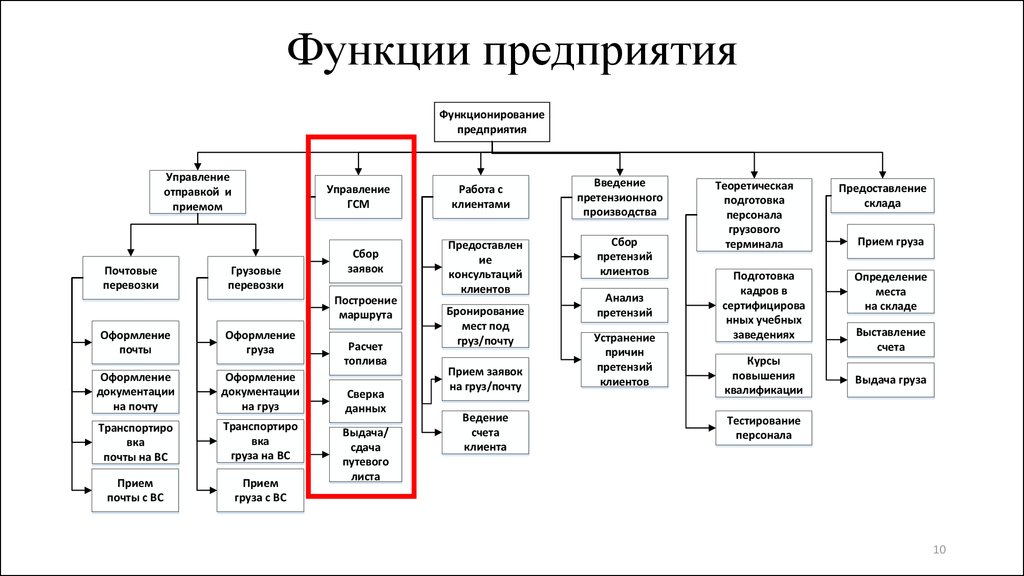 Однако ИП на практике почти никогда их не получают. В число кодов статистики входят коды ОКПО, ОГРН, ОКТМО, ОКФС, ОКОПФ, ОКАТО и, конечно, ОКОГУ. Узнать свои коды статистики можно в территориальном отделении налоговой службы или управлении Росстата, оставив официальный запрос. Ответ на запрос дадут в течение 5 дней.
Однако ИП на практике почти никогда их не получают. В число кодов статистики входят коды ОКПО, ОГРН, ОКТМО, ОКФС, ОКОПФ, ОКАТО и, конечно, ОКОГУ. Узнать свои коды статистики можно в территориальном отделении налоговой службы или управлении Росстата, оставив официальный запрос. Ответ на запрос дадут в течение 5 дней.
Для получения кодов нужно представить паспорт, доверенность, копию устава, свидетельство о госрегистрации и выписку из государственного реестра. При первом обращении уведомление выдается бесплатно, обращаясь повторно, придется заплатить. Юридические компании тоже оказывают услуги по предоставлению кодов статистики. Они берут на себя подачу заявления, получение уведомления и передачу его ИП. За услугу берется небольшая плата, она подходит для занятых предпринимателей, так как все выполняется без вашего присутствия.
Как узнать код ОКОГУ по ИНН онлайн
Есть возможность получить коды статистики абсолютно бесплатно и в кратчайшие сроки, воспользовавшись интернетом.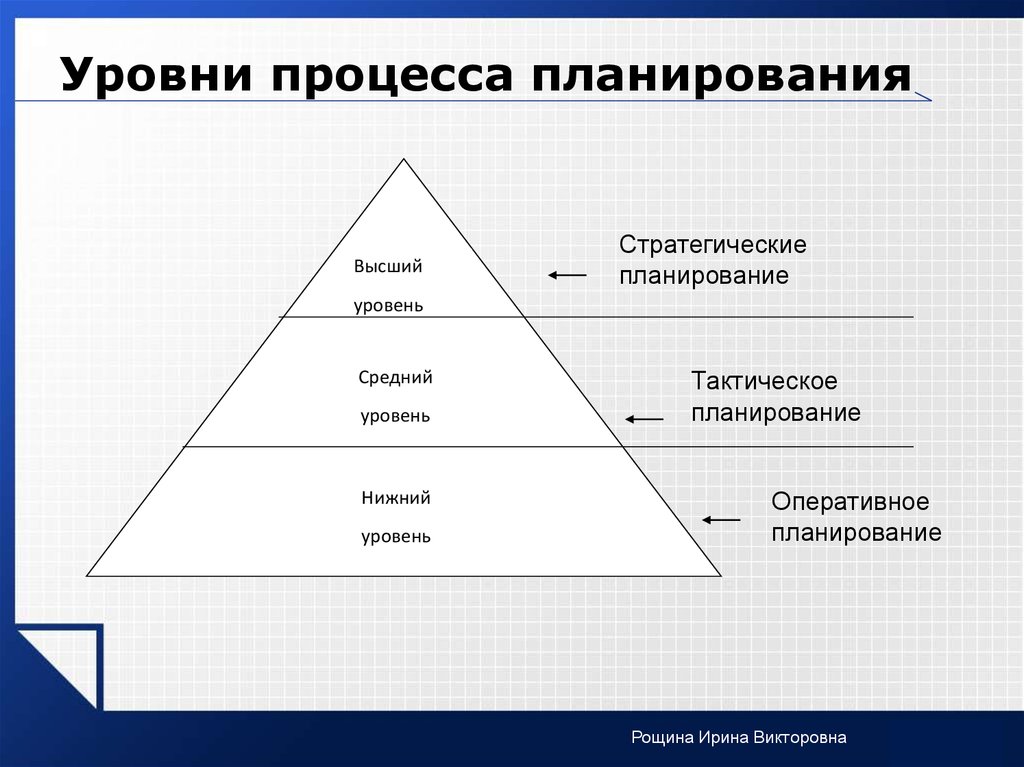 Всегда обращайте внимание на надежность информационного ресурса. Рекомендуется пользоваться официальными сайтами госорганов. Все органы власти имеют сайты, которые оснащены базами данных.
Всегда обращайте внимание на надежность информационного ресурса. Рекомендуется пользоваться официальными сайтами госорганов. Все органы власти имеют сайты, которые оснащены базами данных.
Получить код ОКОГУ по ИНН можно на официальном сайте Росстата по следующему адресу http://statreg.gks.ru/. Для получения информации нужно ввести один из известных реквизитов: ИНН, ОГРН или ОКПО — и ввести контрольный код. Регистрация не требуется. В результате будет сформировано уведомление, содержащее коды статистики, такое же выдается при регистрации.
Имейте в виду, что полученные онлайн уведомления не имеют печати и подписи и носят справочный характер.
Автор статьи: Елизавета Кобрина.
Веб-сервис для малого бизнеса Контур.Бухгалтерия поможет отправлять статистические отчеты и безопасно вести бизнес. Первые 14 дней работы в сервисе — бесплатны. Вы можете вести учет, отправлять отчетность, начислять зарплату и получать консультации наших экспертов.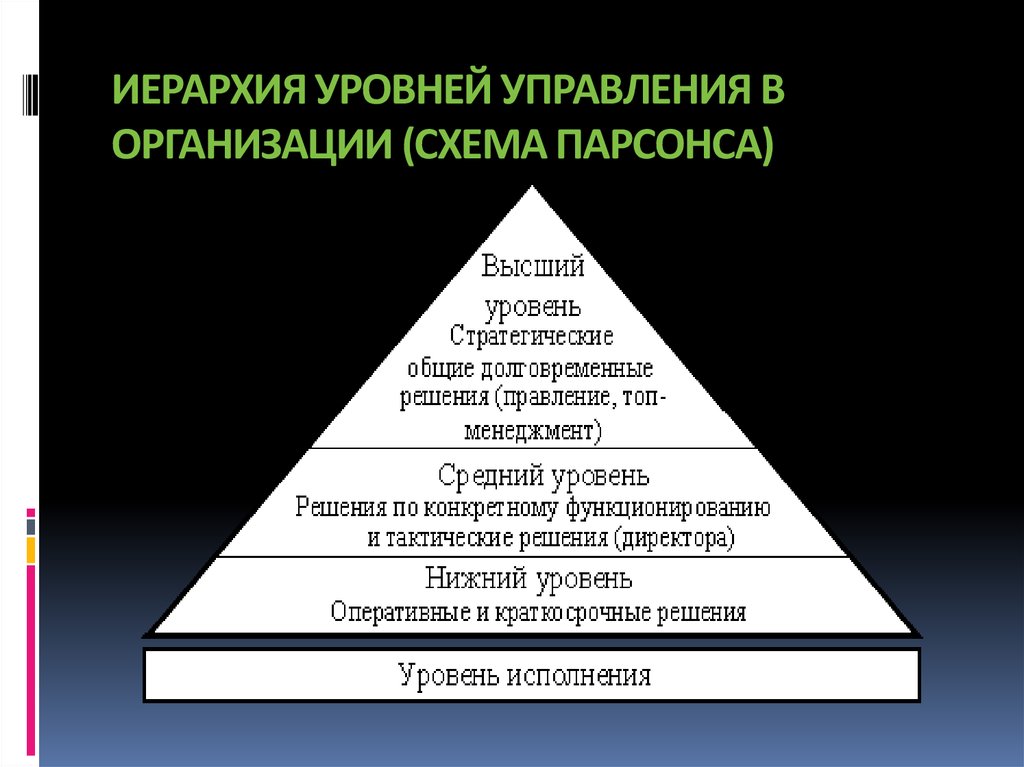
Коды статистики по ИНН для юридических лиц — Бухонлайн
Коды статистики по ИНН для юридических лиц25 мая 2022
Автор Елена Маврицкая
При участии Михаил Пархоменко
Современные сервисы позволяют бесплатно получить по ИНН коды Росстата для юридических лиц и предпринимателей. ОКВЭД по видам деятельности можно посмотреть в выписке, сделанной на сайте ФНС. Если распечатать эту информацию на обычной бумаге, получится действительный документ, который допустимо предъявить в банк или другую инстанцию.
Содержание
- Что такое коды статистики
- Виды кодов статистики и их применение
- Получение кодов онлайн для ООО и ИП
- Как бесплатно получить коды статистики по ИНН онлайн?
Что такое коды статистики
Статистические коды присваивает Федеральная служба государственной статистики (Росстат).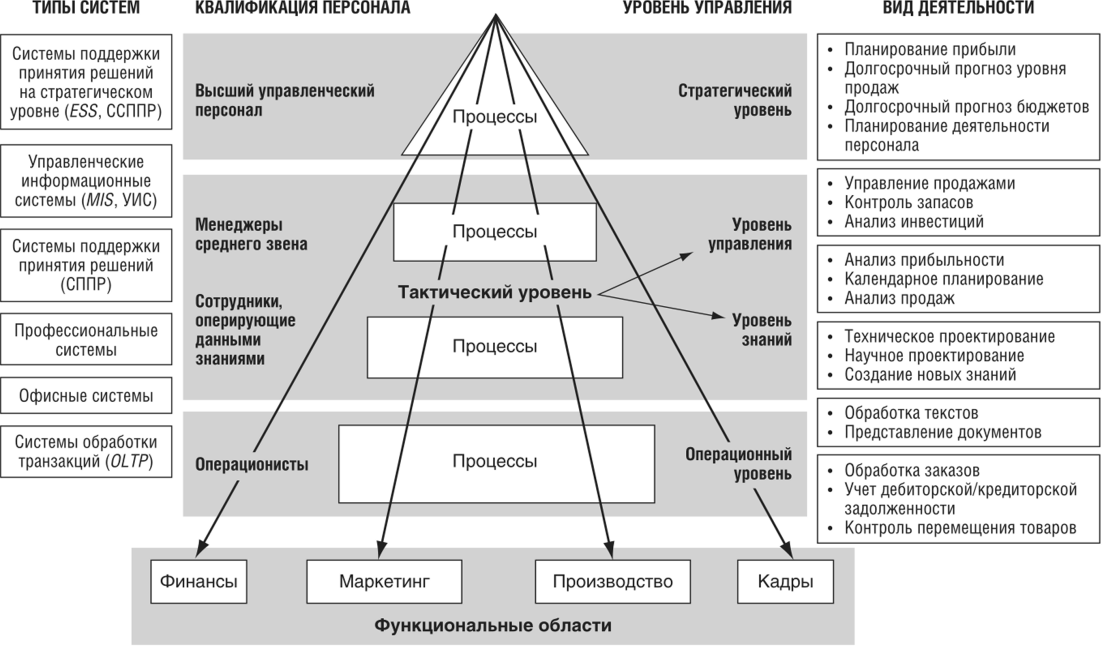 Они содержат информацию об основных характеристиках каждого хозяйствующего субъекта, в том числе каждой организации или ИП. Эта информация представлена в зашифрованном виде.
Они содержат информацию об основных характеристиках каждого хозяйствующего субъекта, в том числе каждой организации или ИП. Эта информация представлена в зашифрованном виде.
Узнать ОКВЭДы, систему налогообложения и доходы вашего контрагента
Без кодов статистики обойтись нельзя. Их нужно указывать в бухгалтерской, налоговой и статистической отчетности, которую регулярно сдают все компании и предприниматели. Плюс к этому данные коды приходится сообщать банкирам, чтобы те открыли расчетный счет.
Виды кодов статистики и их применение
1. ОКПО (общероссийский классификатор предприятий и организаций). Это основной код хозяйствующих субъектов России. Его присваивают всем компаниям, их филиалам и представительствам, а также всем индивидуальным предпринимателям. Без ОКПО деятельность незаконна. У юридических лиц он восьмизначный, у ИП — десятизначный. ОКПО применяется при обмене данными между ведомствами и при статистическом анализе.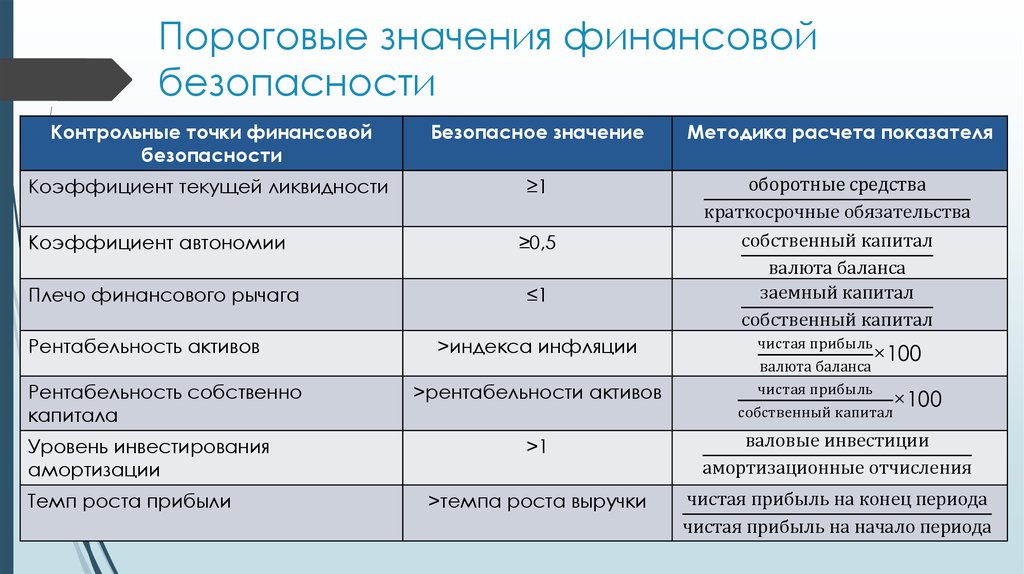
Бесплатно узнать или проверить свой ОКПО, ИНН и другие коды
2. ОКТМО (общероссийский классификатор территорий муниципальных образований). Росстат считывает этот код с отчетности, представленной организацией или предпринимателем. Далее распознает муниципальное образование, к которому относится компания или ИП. Есть ОКТМО, состоящие из 8-ми цифр. Первые две обозначают регион. Цифры с третьей по пятую — муниципальный район, городской округ или внутригородские территории Москвы, Санкт-Петербурга и Севастополя. Цифры с шестой по восьмую — городское поселение, внутригородские районы, сельское поселение или межселенные территории.
Обратите внимание: в веб-сервисах актуальные коды ОКТМО устанавливаются автоматически, без участия пользователя. Бухгалтеру при заполнении отчета остается только выбрать название своего муниципального образования.
3. ОКОПФ (общероссийский классификатор организационно-правовых форм) состоит из пяти цифр. Первая указывает на раздел. Например, коммерческие корпоративные организации объединены в разделе 1, граждане (физлица) — в разделе 5 и проч. Вторая и третья цифры означает тип, а четвертая и пятая — вид организационно-правовой формы. ОКОПФ не уникальны. Существует единый код для всех ООО — 12300, единый для всех ИП — 50102 и т.д. Они используются в информационных ресурсах, которые содержат данные о хозяйствующих субъектах.
Первая указывает на раздел. Например, коммерческие корпоративные организации объединены в разделе 1, граждане (физлица) — в разделе 5 и проч. Вторая и третья цифры означает тип, а четвертая и пятая — вид организационно-правовой формы. ОКОПФ не уникальны. Существует единый код для всех ООО — 12300, единый для всех ИП — 50102 и т.д. Они используются в информационных ресурсах, которые содержат данные о хозяйствующих субъектах.
4. ОКОГУ (общероссийский классификатор органов государственной власти и управления) применяется для удобства статистического наблюдения. Код состоит из семи знаков, первый из которых обозначает группу. Всего есть пять групп. Первая, вторая, третья и пятая предназначены для органов власти или управления: государственных, региональных, муниципальных и межгосударственных. Четвертая группа объединяет организации, по которым осуществляется федеральное статистическое наблюдение. Таким образом, у всех компаний, не относящихся к структурам власти, ОКОГУ начинается с цифры «4».
5. ОКОФС (общероссийский классификатор форм собственности) используется для статистического анализа и формирования различных информационных ресурсов. Этот код двузначный. Первый знак показывает номер группы: «1» — российская собственность, «2» — иностранная, «3» — совместная российская и иностранная, «4» — смешанная российская с долей государственной и т.д. Второй знак обозначат порядковый номер внутри группы. К примеру, ОКОФС «16» присваивается тем, у кого частная российская собственность.
6. ОКВЭД (общероссийский классификатор видов экономической деятельности) показывает виды деятельности, которыми занимается или собирается заниматься компания или ИП. У организации или предпринимателя может быть несколько ОКВЭД. Первый раз их присваивают при регистрации, а затем, если есть необходимость, при смене направлений бизнеса. В настоящее время используется ОКВЭД2 (ОК 029-2014 (КДЕС Ред.2), утвержденный приказом Росстандарта от 31. 01.14 № 14-ст. Этот код указывают во многих видах отчетности, в том числе налоговой. В частности, поле для ОКВЭД есть в форме декларации по НДС.
01.14 № 14-ст. Этот код указывают во многих видах отчетности, в том числе налоговой. В частности, поле для ОКВЭД есть в форме декларации по НДС.
Проверить коды ОКВЭД у «своего» ИП и его контрагентов
Получение кодов онлайн для ООО и ИП
Первый раз документ с кодами (кроме ОКВЭД) вновь зарегистрированная компания или ИП бесплатно получает в Росстате. Несколько лет назад это было свидетельство, скрепленное печатью указанного ведомства. Сейчас и название, и оформление документа стали другими.
СПРАВКА. Современный документ из статистики называется уведомлением. В нем нет печати. Тем не менее он является действительным, и его можно предъявить в банк, а также в любую другую инстанцию.
Есть и еще одно важное новшество. Прежде, если свидетельство с кодами было потеряно, приходилось получать дубликат и платить за это деньги. В настоящее время Росстат не выдает повторных уведомлений.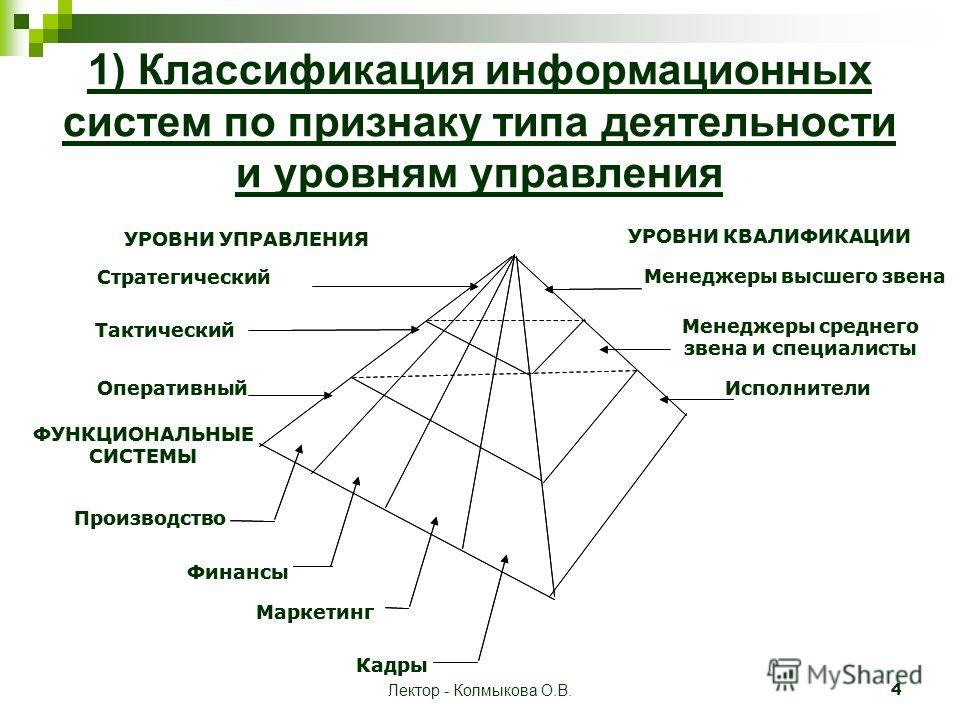 Зато их можно получить самостоятельно в режиме онлайн без какой-либо оплаты.
Зато их можно получить самостоятельно в режиме онлайн без какой-либо оплаты.
Особняком стоят коды ОКВЭД. Они перечислены не в уведомлении Росстата, а в выписке из единого госреестра юридических лиц (ЕГРЮЛ) или предпринимателей (ЕГРИП). Эти реестры ведут налоговики.
Бесплатно подобрать коды ОКВЭД в специальном веб-сервисе
Как бесплатно получить коды статистики по ИНН онлайн?
ООО или ИП может скачать по ИНН и распечатать информацию из органов статистики (кроме ОКВЭД) на онлайн-сервисе Росстата. Нужно ввести на выбор ОКПО, ИНН, либо ОГРН и нажать «Получить».
ВНИМАНИЕ. Для повторного получения ОКВЭД следует бесплатно сформировать выписку из ЕГРЮЛ или ЕГРИП. Сделать это можно на сайте Федеральной налоговой службы. Здесь надо ввести ИНН, ОГРН или название организации (фамилию и имя ИП). Чтобы быстрее найти нужное ООО, либо предпринимателя, лучше дополнительно указать регион, выбрав его из списка.

Далее следует распечатать полученное по ИНН уведомление или выписку с кодами статистики. Не обязательно использовать фирменный бланк, подойдет обычная бумага. Несмотря на отсутствие печати и подписи должностного лица, документ является официальным.
Проверить себя или контрагента по санкционным спискам Проверить бесплатно
В закладкиПоделиться
16 141
Ложный коэффициент обнаружения | Columbia Public Health
Overview | Software |
Description | Websites |
Readings | Courses |
Overview
На этой странице кратко описывается коэффициент ложного обнаружения (FDR) и приводится аннотированный список ресурсов.
Описание
При анализе результатов полногеномных исследований часто одновременно проводятся тысячи проверок гипотез. Использование традиционного метода Бонферрони для корректировки множественных сравнений является слишком консервативным, поскольку защита от ложноположительных результатов приведет к большому количеству упущенных результатов. Чтобы иметь возможность идентифицировать как можно больше значимых сравнений, сохраняя при этом низкий уровень ложных срабатываний, используется коэффициент ложного обнаружения (FDR) и его аналог — значение q.
Постановка задачи
При проверке гипотезы, например, чтобы увидеть, существенно ли различаются два средних значения, мы вычисляем p-значение, которое представляет собой вероятность получения тестовой статистики, которая является такой же или более экстремальной, чем наблюдаемая. , при условии, что нулевая гипотеза верна. Например, если бы у нас было значение p, равное 0,03, это означало бы, что если наша нулевая гипотеза верна, то вероятность получения наблюдаемой нами тестовой статистики составляет 3% или более экстремальная. Поскольку это малая вероятность, мы отклоняем нулевую гипотезу и говорим, что средние значения существенно различаются. Обычно мы предпочитаем держать эту вероятность ниже 5%. Когда мы устанавливаем нашу альфу на 0,05, мы говорим, что хотим, чтобы вероятность того, что нулевой результат будет назван значимым, была меньше 5%. Другими словами, мы хотим, чтобы вероятность ошибки первого рода или ложного срабатывания была меньше 5 %.
Поскольку это малая вероятность, мы отклоняем нулевую гипотезу и говорим, что средние значения существенно различаются. Обычно мы предпочитаем держать эту вероятность ниже 5%. Когда мы устанавливаем нашу альфу на 0,05, мы говорим, что хотим, чтобы вероятность того, что нулевой результат будет назван значимым, была меньше 5%. Другими словами, мы хотим, чтобы вероятность ошибки первого рода или ложного срабатывания была меньше 5 %.
Когда мы проводим множественные сравнения (каждый тест я буду называть «функцией»), у нас повышается вероятность ложных срабатываний. Чем больше у вас функций, тем выше шансы, что нулевая функция будет признана значимой. Частота ложных срабатываний (FPR) или частота ошибок сравнения (PCER) — это ожидаемое количество ложноположительных результатов из всех проведенных тестов гипотез. Таким образом, если мы контролируем FPR с альфой 0,05, мы гарантируем, что процент ложных срабатываний (нулевые признаки, называемые значимыми) из всех проверок гипотез составляет 5% или меньше. Этот метод создает проблему, когда мы проводим большое количество проверок гипотез. Например, если бы мы проводили полногеномное исследование, изучая дифференциальную экспрессию генов между опухолевой тканью и здоровой тканью, и мы протестировали 1000 генов и контролировали FPR, в среднем 50 действительно нулевых генов будут названы значимыми. Этот метод слишком либерален, так как мы не хотим иметь такое большое количество ложных срабатываний.
Этот метод создает проблему, когда мы проводим большое количество проверок гипотез. Например, если бы мы проводили полногеномное исследование, изучая дифференциальную экспрессию генов между опухолевой тканью и здоровой тканью, и мы протестировали 1000 генов и контролировали FPR, в среднем 50 действительно нулевых генов будут названы значимыми. Этот метод слишком либерален, так как мы не хотим иметь такое большое количество ложных срабатываний.
Как правило, множественные процедуры сравнения вместо этого контролируют коэффициент ошибок для всей семьи (FWER), который представляет собой вероятность получения одного или нескольких ложноположительных результатов из всех проведенных проверок гипотез. Обычно используемая поправка Бонферрони управляет FWER. Если мы проверяем каждую гипотезу на уровне значимости (альфа/количество проверок гипотез), мы гарантируем, что вероятность наличия одного или нескольких ложных срабатываний меньше, чем альфа. Таким образом, если бы альфа был равен 0,05 и мы тестировали наши 1000 генов, мы бы проверили каждое значение p на уровне значимости 0,00005, чтобы гарантировать, что вероятность одного или нескольких ложных срабатываний составляет 5% или меньше. Однако защита от любого отдельного ложноположительного результата может быть слишком строгой для полногеномных исследований и может привести к множеству упущенных результатов, особенно если мы ожидаем, что будет много истинно положительных результатов.
Однако защита от любого отдельного ложноположительного результата может быть слишком строгой для полногеномных исследований и может привести к множеству упущенных результатов, особенно если мы ожидаем, что будет много истинно положительных результатов.
Контроль частоты ложных срабатываний (FDR) – это способ определить как можно больше важных функций, при этом доля ложных срабатываний относительно невелика.
Шаги для контроля частоты ложных открытий:
E[V/R]
P(i) ≤ α × i/m
Если верно, то значительна
*Ограничение: если частота ошибок (α) очень велика может привести к увеличению числа ложноположительных результатов среди значимых результатов
Коэффициент ложных открытий (FDR)
FDR — это скорость, при которой характеристики, называемые значимыми, действительно нулевые.
FDR = ожидаемый (количество ложных прогнозов/количество прогнозов)
FDR — это доля признаков, называемых значимыми, действительно нулевыми. FDR, равный 5 %, означает, что среди всех признаков, называемых значимыми, 5 % действительно нулевые. Точно так же, как мы устанавливаем альфу в качестве порога для p-значения для управления FPR, мы также можем установить порог для q-значения, которое является аналогом FDR для p-значения. Порог p-значения (альфа) 0,05 дает FPR 5% среди всех действительно нулевых признаков. Пороговое значение q, равное 0,05, дает FDR 5% среди всех признаков, называемых значимыми. Значение q представляет собой ожидаемую долю ложных срабатываний среди всех признаков, таких же или более экстремальных, чем наблюдаемые.
FDR, равный 5 %, означает, что среди всех признаков, называемых значимыми, 5 % действительно нулевые. Точно так же, как мы устанавливаем альфу в качестве порога для p-значения для управления FPR, мы также можем установить порог для q-значения, которое является аналогом FDR для p-значения. Порог p-значения (альфа) 0,05 дает FPR 5% среди всех действительно нулевых признаков. Пороговое значение q, равное 0,05, дает FDR 5% среди всех признаков, называемых значимыми. Значение q представляет собой ожидаемую долю ложных срабатываний среди всех признаков, таких же или более экстремальных, чем наблюдаемые.
В нашем исследовании 1000 генов, скажем, ген Y имел p-значение 0,00005 и q-значение 0,03. Вероятность того, что тестовая статистика недифференциально экспрессируемого гена будет такой же или более экстремальной, как тестовая статистика для гена Y, составляет 0,00005. Однако тестовая статистика гена Y может быть очень экстремальной, и, возможно, эта тестовая статистика маловероятна для дифференциально экспрессируемого гена. Вполне возможно, что действительно существуют дифференциально экспрессируемые гены с тестовой статистикой менее экстремальной, чем у гена Y. Использование значения q, равного 0,03, позволяет нам сказать, что 3% генов являются такими же или более экстремальными (т. значения) как ген Y являются ложноположительными. Использование q-значений позволяет нам решить, сколько ложных срабатываний мы готовы принять среди всех функций, которые мы называем значимыми. Это особенно полезно, когда мы хотим сделать большое количество открытий для дальнейшего подтверждения позже (например, пилотное исследование или предварительный анализ, например, если мы сделали микрочип экспрессии генов, чтобы выбрать дифференциально экспрессируемые гены для подтверждения с помощью ПЦР в реальном времени). Это также полезно в исследованиях всего генома, когда мы ожидаем, что значительная часть признаков будет действительно альтернативной, и мы не хотим ограничивать наши возможности открытия.
Вполне возможно, что действительно существуют дифференциально экспрессируемые гены с тестовой статистикой менее экстремальной, чем у гена Y. Использование значения q, равного 0,03, позволяет нам сказать, что 3% генов являются такими же или более экстремальными (т. значения) как ген Y являются ложноположительными. Использование q-значений позволяет нам решить, сколько ложных срабатываний мы готовы принять среди всех функций, которые мы называем значимыми. Это особенно полезно, когда мы хотим сделать большое количество открытий для дальнейшего подтверждения позже (например, пилотное исследование или предварительный анализ, например, если мы сделали микрочип экспрессии генов, чтобы выбрать дифференциально экспрессируемые гены для подтверждения с помощью ПЦР в реальном времени). Это также полезно в исследованиях всего генома, когда мы ожидаем, что значительная часть признаков будет действительно альтернативной, и мы не хотим ограничивать наши возможности открытия.
FDR обладает некоторыми полезными свойствами. Если все нулевые гипотезы верны (истинно альтернативных результатов нет), то FDR=FWER. Когда имеется некоторое количество действительно альтернативных гипотез, контроль FWER автоматически также контролирует FDR.
Мощность метода FDR (напомним, что мощность — это вероятность отклонения нулевой гипотезы, когда альтернатива верна) равномерно больше, чем у методов Бонферрони. Преимущество FDR по мощности над методами Бонферрони увеличивается с увеличением числа проверок гипотез.
Оценка FDR
(Из Стори и Тибширани, 2003)
Определения:t: порог V: количество ложноположительных результатовS: количество признаков, называемых значимымиm0: количество действительно нулевых признаковm: общее количество проверок гипотез (признаков)
FDR при определенном пороге t равен FDR(t). FDR(t) ≈ E[V(t)]/E[S(t)] —> FDR при определенном пороге можно оценить как ожидаемое количество ложных срабатываний при этом пороге, деленное на ожидаемое количество признаков, называемых значимыми. у того порога.
Как мы оцениваем E[S(t)]?
E[S(t)] — это просто S(t), число наблюдаемых p-значений ≤ t (т. е. количество признаков, которые мы называем значимыми при выбранном пороге). Вероятность того, что нулевое значение p ≤ t, равна t (когда альфа = 0,05, существует 5% вероятность того, что действительно нулевой признак имеет p-значение, которое случайно ниже порогового значения и поэтому называется значимым).
Как мы оцениваем E[V(t)]?
E[V(t)]=m0*t —> ожидаемое количество ложных срабатываний для заданного порога равно количеству действительно нулевых признаков, умноженному на вероятность того, что нулевой признак будет назван значимым.
Как мы оцениваем m0?
Истинное значение m0 неизвестно. Мы можем оценить долю признаков, которые действительно нулевые, m0/m = π0.
Мы предполагаем, что p-значения нулевых признаков будут равномерно распределены (имеют плоское распределение) между [0,1]. Высота плоского распределения дает консервативную оценку общей доли нулевых p-значений, π0. Например, изображение ниже, взятое из Стори и Тибширани (2003), представляет собой гистограмму плотности 3000 p-значений для 3000 генов из исследования экспрессии генов. Пунктирная линия представляет собой высоту плоской части гистограммы. Мы ожидаем, что действительно нулевые признаки будут формировать это плоское распределение от [0,1], а истинно альтернативные признаки будут ближе к 0,9.0050
π0 количественно определяется как , где лямбда — это параметр настройки (например, на изображении выше мы можем выбрать лямбда = 0,5, поскольку после значения р 0,5 распределение становится довольно плоским. Доля действительно нулевых признаков равна число p-значений, превышающих лямбда, деленное на m(1-лямбда).Поскольку лямбда приближается к 0 (когда большая часть распределения является плоской), знаменатель будет приблизительно равен m, как и числитель, поскольку большинство p-значений будет больше лямбда, а π0 будет приблизительно равно 1 (все признаки равны нулю).
Выбор лямбда обычно автоматизирован статистическими программами.
Теперь, когда мы оценили π0, мы можем оценить FDR(t) как
. Числитель для этого уравнения — это просто ожидаемое количество ложных срабатываний, поскольку π0*m — это оценочное количество истинно нулевых гипотез, а t — вероятность действительно нулевой признак называется значимым (ниже порога t). Знаменатель, как мы сказали выше, — это просто количество признаков, называемых значимыми.
В этом случае значение q для признака является минимальным FDR, которого можно достичь, если назвать этот признак значимым.
(Примечание: вышеприведенные определения предполагают, что m очень велико, поэтому S>0. Когда S=0, FDR не определен, поэтому в литературе по статистике величина E[V/S|S>0]*Pr( S>0) используется в качестве FDR. В качестве альтернативы используется положительный FDR (pFDR), который равен E[V/S|S>0]. Подробнее см. Benjamini and Hochberg (1995) и Storey and Tibshirani (2003). информация.)
Литература
Учебники и главы
«ПОСЛЕДНИЕ ДОСТИЖЕНИЯ В БИОСТАТИСТИКЕ (Том 4):
Частота ложных открытий, анализ выживаемости и связанные темы»
Под редакцией Маниша Бхаттачарджи (Технологический институт Нью-Джерси, США), Сунила К. Дхара (Технологический институт Нью-Джерси, США) и Сундаррамана Субраманиана (Технологический институт Нью-Джерси, США).
http://www.worldscibooks.com/lifesci/8010.html
В первой главе этой книги дается обзор процедур контроля FDR, предложенных видными статистиками в этой области, и предлагается новый адаптивный метод, который контролирует FDR, когда p-значения независимы или положительно зависимы.
«Интуитивная биостатистика: нематематическое руководство по статистическому мышлению»
Харви Мотулски
http://www.amazon.com/Intuitive-Biostatistics-Nonmathematical-Statistical-Thinking/dp/product-description/0199730067
Это книга статистических данных, написанных для ученых, не имеющих сложной статистической подготовки. В части E, «Проблемы в статистике», простыми словами объясняется проблема множественных сравнений и различные способы ее решения, включая базовые описания коэффициента ошибок по признаку семейства и FDR.
«Крупномасштабный вывод: эмпирические байесовские методы оценки, тестирования и прогнозирования»
, Эфрон, Б. (2010 г.). Монографии Института математической статистики, издательство Кембриджского университета.
http://www.amazon.com/gp/product/0521192498/ref=as_li_ss_tl?ie=UTF8&tag=chrprobboo-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=0521192498
В этой книге рассматривается концепция FDR и исследуется ее ценность. не только как процедура оценки, но и как объект проверки значимости. Автор также дает эмпирическую оценку точности оценок FDR.
Методологические статьи
Benjamini, Y. and Y. Hochberg (1995). «Контроль уровня ложных открытий: практичный и мощный подход к множественному тестированию». Журнал Королевского статистического общества. Серия Б (методическая) 57(1): 289-300.
Эта статья 1995 года была первым официальным описанием FDR. Авторы математически объясняют, как FDR соотносится с коэффициентом семейных ошибок (FWER), приводят простой пример того, как использовать FDR, и проводят имитационное исследование, демонстрирующее эффективность процедуры FDR по сравнению с процедурами типа Бонферрони.
Стори, Дж. Д. и Р. Тибширани (2003). «Статистическая значимость для полногеномных исследований». Труды Национальной академии наук 100 (16): 9440-9445.
В этом документе объясняется, что такое FDR и почему он важен для полногеномных исследований, а также объясняется, как можно оценить FDR. В нем приведены примеры ситуаций, в которых FDR был бы полезен, и приведен пример того, как авторы использовали FDR для анализа данных дифференциальной экспрессии генов на микрочипах.
Этаж JD. (2010) Частота ложных открытий. В Международной энциклопедии статистических наук, Ловрик М. (редактор).
Очень хорошая статья, посвященная контролю FDR, положительному FDR (pFDR) и зависимости. Рекомендуется получить упрощенный обзор FDR и связанных с ним методов для множественных сравнений.
Райнер А., Йекутиели Д., Бенджамини Ю.: Идентификация генов с дифференциальной экспрессией с использованием процедур контроля частоты ложных открытий. Биоинформатика 2003, 19(3):368-375.
В этой статье используются смоделированные данные микроматрицы для сравнения трех процедур управления FDR на основе повторной выборки с процедурой Бенджамини-Хохберга. Повторная выборка тестовой статистики выполняется таким образом, чтобы не предполагать распределение тестовой статистики дифференциальной экспрессии каждого гена.
Верховен К. Дж. Ф., Симонсен К. Л., Макинтайр Л. М.: Внедрение контроля частоты ложных обнаружений: увеличение вашей мощности. Ойкос 2005, 108(3):643-647.
В этом документе объясняется процедура Бенджамини-Хохберга, приводится пример моделирования и обсуждаются последние разработки в области FDR, которые могут обеспечить большую мощность, чем исходный метод FDR.
Стэн Паундс и Ченг Ченг (2004) «Улучшение оценки частоты ложных открытий» Bioinformatics Vol. 20 нет. 11 2004 г., страницы 1737–1745.
В этом документе представлен метод, называемый гистограммой LOESS (SPLOSH). Этот метод предлагается для оценки условного FDR (cFDR), ожидаемой доли ложноположительных результатов, обусловленных наличием k «значимых» результатов.
Daniel Yekutieli , Yoav Benjamini (1998) «Уровень ложного обнаружения на основе повторной выборки, контролирующий несколько тестовых процедур для коррелированной тестовой статистики» Journal of Statistical Planning and Inference 82 (1999) 171-196.
В этом документе представлена новая процедура управления FDR для работы со статистическими данными испытаний, которые коррелируют друг с другом. Метод включает вычисление p-значения на основе повторной выборки. Свойства этого метода оцениваются с помощью имитационного исследования.
Йоав Бенджамини и Даниэль Екутиели (2001) «Контроль частоты ложных открытий при множественном тестировании в условиях зависимости» Статистические анналы 2001, Vol. 29, № 4, 1165–1188.
Метод FDR, который был первоначально предложен, предназначался для использования при множественной проверке гипотез независимой тестовой статистики. В этой статье показано, что исходный метод FDR также контролирует FDR, когда статистика теста имеет положительную регрессионную зависимость от каждой статистики теста, соответствующей истинной нулевой гипотезе. Примером зависимой тестовой статистики может быть тестирование нескольких конечных точек между лечебной и контрольной группами в клиническом испытании.
Джон Д. Стори (2003) «Коэффициент положительных ложных открытий: байесовская интерпретация и значение q» Статистические анналы 2003, Vol. 31, № 6, 2013–2035 гг.
В этом документе определяется коэффициент положительных ложных открытий (pFDR), который представляет собой ожидаемое количество ложных срабатываний из всех тестов, называемых значимыми, при условии, что имеется хотя бы один положительный результат. В документе также представлена байесовская интерпретация pFDR.
Юди Павитан, Стефан Михилс, Серж Косельни, Ариф Гуснанто и Александр Плонер (2005 г.) «Частота ложных открытий, чувствительность и размер выборки для исследований микрочипов» Bioinformatics Vol. 21 нет. 13 2005 г., страницы 3017–3024.
В этой статье описывается метод расчета размера выборки для двухвыборочного сравнительного исследования, основанный на контроле FDR и чувствительности.
Grant GR, Liu J, Stoeckert CJ Jr. (2005) Практический подход к выявлению паттернов дифференциальной экспрессии в данных микрочипов. Биоинформатика. 2005, 21(11): 2684-90.
Авторы описывают методы оценки перестановок и обсуждают вопросы, связанные с выбором исследователем статистических методов и методов преобразования данных. Также исследуется оптимизация мощности, связанная с использованием данных микрочипов.
Цзяньцин Фань, Фредерик Л. Мур, Сюй Хань, Вейцзе Гу, Оценка доли ложных открытий при произвольной ковариационной зависимости. J Am Stat Assoc. 2012 г.; 107(499): 1019–1035.
В данной статье предлагается и описывается метод управления FDR, основанный на аппроксимации главного фактора ковариационной матрицы тестовой статистики.
Статьи по применению
Хан С., Ли К.М., Парк С.К., Ли Дж.Э., Ан Х.С., Шин Х.И., Кан Х.Дж., Ку Х.Х., Сео Дж.Дж., Чой Дж.Е. и др.: Полногеномное ассоциативное исследование детского острого лимфобластного лейкоза в Корее . Исследование лейкемии 2010, 34(10):1271-1274.
Это было полногеномное ассоциативное исследование (GWAS), в котором тестировался один миллион однонуклеотидных полиморфизмов (SNP) на предмет связи с детским актутным лимфобластным лейкозом (ALL). Они контролировали FDR на уровне 0,2 и обнаружили, что 6 SNP в 4 разных генах тесно связаны с риском ОЛЛ.
Педерсен, К.С., Бамлет, В.Р., Оберг, А.Л., де Андраде, М., Мацумото, М.Е., Тан, Х., Тибодо, С.Н., Петерсен, Г.М. и Ван, Л. (2011). Сигнатура метилирования ДНК лейкоцитов отличает пациентов с раком поджелудочной железы от здорового контроля. PLoS ONE 6, e18223.
В этом исследовании контролировался FDR <0,05 при поиске дифференциально метилированных генов между пациентами с аденомой поджелудочной железы и здоровым контролем для поиска эпигенетических биомаркеров заболевания.
Daniel W. Lin, Liesel M. FitzGerald, Rong Fu, Erika M. Kwon, Siqun Lilly Zheng, Suzanne et al. Генетические варианты генов LEPR, CRY1, RNASEL, IL4 и ARVCF являются прогностическими маркерами рака предстательной железы -Удельная смертность (2011 г.), Биомаркеры эпидемиола рака, предыдущая версия, 2011 г.; 20:19.28-1936. В этом исследовании изучались вариации в выбранных генах-кандидатах, связанных с возникновением рака предстательной железы, чтобы проверить их прогностическую ценность среди лиц с высоким риском. FDR использовали для ранжирования однонуклеотидных полиморфизмов (SNP) и выявления представляющих интерес SNP высшего ранга.
Радом-Айзик С., Залдивар Ф., Леу С.Ю., Адамс Г.Р., Оливер С., Купер Д.М.: Влияние упражнений на экспрессию микроРНК в мононуклеарных клетках периферической крови молодых мужчин. Клиническая и трансляционная наука 2012, 5(1):32–38.
В этом исследовании изучали изменение экспрессии микроРНК до и после тренировки с использованием микроматрицы. Они использовали процедуру Бенджамини-Хохберга для контроля FDR на уровне 0,05 и обнаружили, что 34 из 236 микроРНК экспрессируются по-разному. Затем исследователи выбрали микроРНК из этих 34 для подтверждения с помощью ПЦР в реальном времени.
Веб-сайты
Статистический пакет R
http://genomine.org/qvalue/results.html
Аннотированный код R, используемый для анализа данных в статье Стори и Тибширани (2003), включая ссылку на файл данных. Этот код можно адаптировать для работы с любыми данными массива.
http://www.bioconductor.org/packages/release/bioc/html/qvalue.html
пакет qvalue для R.
http://journal.r-project.org/archive/2009-1/RJournal_2009 -1.pdf
Журнал R Project — это рецензируемая публикация с открытым доступом R Foundation for Statistical Computing. В этом томе представлена статья Меган Орр и Пэн Лю под названием «Оценка размера выборки при контроле уровня ложных открытий для экспериментов с микрочипами». Приведены конкретные функции и подробные примеры.
http://strimmerlab.org/notes/fdr.html
На этом веб-сайте представлен список программного обеспечения R для анализа FDR со ссылками на их домашние страницы для описания функций пакета.
SAS
http://support.sas.com/documentation/cdl/en/statug/63347/HTML/default/viewer.htm#statug_multtest_sect001.htm
Описание PROC MULTTEST в SAS, который предоставляет опции для управления FDR используя разные методы.
STATA
http://www.stata-journal.com/article.html?article=st0209
Предоставляет команды STATA для вычисления значений q для процедур с несколькими тестами (вычисление значений q, скорректированных FDR).
FDR_общие веб-ресурсы
http://www.math.tau.ac.il/~ybenja/fdr/index.htm
Веб-сайт, управляемый статистиками Тель-Авивского университета, которые впервые официально представили FDR.
http://www.math.tau.ac.il/~ybenja/
На этом веб-сайте Рузвельта имеется множество ссылок. Лекция о ФДР доступна для ознакомления.
http://www.cbil.upenn.edu/PaGE/fdr.html
Красивое, лаконичное объяснение FDR. Предоставляется полезная краткая сводка с примером.
http://www.rowett.ac.uk/~gwh/False-positives-and-the-qvalue.pdf
Краткий обзор ложных срабатываний и значений q.
Курсы
Учебное пособие по контролю за ложными открытиями Кристофера Р. Дженовезе Статистического факультета Университета Карнеги-Меллона.
Этот PowerPoint представляет собой очень подробное руководство для тех, кто заинтересован в изучении математических основ FDR и его вариаций.
Множественное тестирование, Джошуа Акей, Департамент геномных наук, Вашингтонский университет.
Этот PowerPoint обеспечивает очень интуитивное понимание множественных сравнений и FDR. Эта лекция хороша для тех, кто ищет простое понимание Рузвельта без большого количества математики.
Оценка локальной частоты ложных обнаружений при обнаружении дифференциального выражения между двумя классами.
Презентация Джеффри Маклахлана, профессора Университета Квинсленда, Австралия.
www.youtube.com/watch?v=J4wn9_LGPcY
Эта видеолекция была полезна для изучения местного FDR, который представляет собой вероятность того, что конкретная гипотеза верна, учитывая ее конкретную тестовую статистику или p-значение.
Процедуры контроля скорости ложных открытий для дискретных тестов
Презентация Рут Хеллер, профессора кафедры статистики и исследования операций. Тель-Авивский университет
http://www.youtube.com/watch?v=IGjElkd4eS8
Эта видеолекция помогла узнать о применении FDR-управления дискретными данными. Обсуждаются несколько процедур повышения и понижения для управления FDR при работе с дискретными данными. Рассматриваются альтернативы, которые в конечном итоге помогают увеличить мощность.
COVID-19: Данные штата Мэн| Коронавирусная болезнь 2019 (COVID-19) | Программа эпидемиологического надзора за воздушно-капельными инфекциями | MeCDC
Чтобы не отставать от мер реагирования штата Мэн на COVID-19, CDC штата Мэн возвращается к обычной работе. В результате данные о случаях COVID-19 будут обновляться еженедельно по вторникам. Данные о случаях не будут обновляться в праздничные дни. Все данные являются предварительными и могут измениться по мере расследования случаев CDC штата Мэн. Дополнительные сведения о данных см. в разделе «О данных» ниже.
Данные о случаях COVID-19 обновляются еженедельно по вторникам.
Загрузите CSV-файлы с самыми последними совокупными данными о случаях по
почтовый индекс (CSV),
округ (CSV),
возраст (CSV),
пол (CSV),
раса (CSV) и
этническая принадлежность (CSV).
Загрузите CSV-файл с историческими данными о случаях по округам и датам.
Загрузите CSV-файл с историческим количеством смертей, связанных с COVID, по округам, возрастным группам, полу и дате.
Посмотреть полную панель вакцинации от COVID-19 в штате Мэн.
Ежедневные лабораторные результаты COVID-19, новые ежедневные смерти, госпитализированные пациенты и синдромные данные
Динамика случаев COVID-19
Загрузите CSV-файлы с самыми последними совокупными данными о случаях почтовый индекс (CSV), округ (CSV), возраст (CSV), пол (CSV), раса (CSV) и этническая принадлежность (CSV).
Загрузите CSV-файл с историческими данными о случаях по округам и датам.
Совокупное число случаев COVID-19 по округам
Загрузите CSV-файл с последними совокупными данными о случаях заболевания по округам.
Загрузите CSV-файл с историческими данными о случаях по округам и датам.
Совокупное число случаев COVID-19 по почтовому индексу
Загрузите CSV-файл с самыми последними совокупными данными о случаях заболевания по почтовому индексу.
Таблицы данных тестирования на COVID-19, использования в больницах и демографических данных
Просмотр данных тестирования сточных вод
Загрузить отчеты об испытаниях сточных вод CDC штата Мэн
Люди, зараженные вирусом, вызывающим COVID-19, могут выделять его с водой, которая течет из их домов в общественные канализационные системы. Это происходит независимо от того, есть у них симптомы или нет. Сообщества могут отслеживать активность вируса, ища вирусную РНК в сточных водах. Сточные воды или нечистоты включают воду, которая может содержать отходы жизнедеятельности человека (туалеты, душевые, раковины). Сюда же относятся воды из некоторых других источников (дождевая вода, вода для производственных нужд). Чтобы лучше понять бремя COVID-19в сообществе CDC штата Мэн и CDC США проверяют сточные воды на наличие вируса. Это помогает адаптировать действия общественного здравоохранения для защиты сообществ по всему штату.
Найдите эти данные в системе отслеживания данных COVID CDC США. Данные будут добавляться в Data Tracker по мере их появления.
Просмотреть таблицу текущих данных об использовании и вместимости больниц в штате Мэн COVID-19
Просмотреть общее количество случаев прорыва вакцины против COVID-19 в штате Мэн
Случаи прорыва вакцины против COVID-19 среди лиц, которые были полностью вакцинированы, называются прорывом вакцины случаи. Госпитализации и смерти среди этих случаев называются госпитализациями и смертями в результате прорыва вакцины. Человек считается полностью вакцинированным через 14 дней после прохождения первичной вакцинации против COVID-19.серия вакцин (например, 2 дозы вакцин Pfizer или Moderna или 1 доза вакцины J&J). Вакцины против COVID-19, разрешенные или одобренные FDA США, чрезвычайно безопасны и эффективны и предотвращают многие инфекции, госпитализации и смерти. Однако эти вакцины не эффективны на 100%, и ожидаются случаи прорыва вакцины. Исследования, проведенные в других местах в США, показали, что у людей, инфицированных COVID-19 после вакцинации, гораздо меньше шансов на тяжелое заболевание (включая госпитализацию и смерть), чем у людей, которые не были вакцинированы. Дополнительные и бустерные дозы, если они рекомендованы, обеспечивают дополнительную защиту от инфекции, госпитализации и смерти и не отражены в приведенных здесь цифрах. Больше информации о COVID-19инфекции после вакцинации можно найти на федеральном веб-сайте CDC.
Информацию о местах вакцинации в штате Мэн можно найти здесь.
CDC штата Мэн еженедельно обновляет эти данные.
CDC штата Мэн больше не показывает сводные данные о прорыве по состоянию на 14 февраля 2023 года. К настоящему времени 83,4% всего населения штата закончили свою первую серию вакцин. Таким образом, «прорывные» случаи COVID больше не являются полезным способом узнать бремя болезни. Будьте в курсе вашего COVID-19вакцины — лучший способ предотвратить самые тяжелые последствия COVID-19. Это включает в себя защиту от госпитализации и смерти.
Просмотреть отчет о секвенировании генома COVID-19
CDC штата Мэн каждую неделю отправляет несколько образцов с положительным тестом на SARS-CoV-2 для секвенирования генома для мониторинга вариантов. Дополнительную информацию о вариантах можно найти на федеральном веб-сайте CDC.
Загрузите последний отчет о секвенировании генома COVID-19 (PDF)
CDC штата Мэн обновляет эти данные по мере появления новых отчетов.
Обновлено 21 февраля 2023 г., 09:51.
Просмотр данных о COVID-19 и молодежи в штате Мэн
Загрузить PDF-файл с данными о COVID-19 и молодежи в штате Мэн (PDF)
CDC штата Мэн обновляет эти данные по мере появления новых отчетов.
Обновлено 27 февраля 2023 г., 15:10.
О данных
Когда обновляются данные? Данные о делах обновляются еженедельно по вторникам. Другие источники данных могут иметь другие графики обновления.
Кто включен в данные? Данные касаются лиц, заявивших о проживании в штате Мэн, независимо от того, в каком штате они прошли тестирование или где проживают в настоящее время. Например, лицо, заявившее, что оно проживает в штате Мэн, но проживающее во Флориде, появится в этих данных, даже если оно проживало во Флориде на момент болезни. Списки округов составляются по месту жительства пациента, а не по местонахождению больницы или места проведения тестирования.
Что такое подтвержденные случаи? Это количество людей, у которых РНК SARS-CoV-2 была обнаружена с помощью теста молекулярной амплификации (например, ПЦР) в любой утвержденной лаборатории.
Что такое вероятные случаи? Это количество людей, у которых был обнаружен специфический антиген SARS-CoV-2 с помощью диагностического теста, проведенного сертифицированным CLIA поставщиком. Сюда не входят домашние тесты на антигены, взятые самостоятельно. Определения случаев Совета государственных и территориальных эпидемиологов (CSTE) со временем изменились. Здесь вы найдете определения прежних случаев CSTE.
Что такое неопределенный тест? Неопределенный означает, что тест не дал однозначного отрицательного или положительного результата.
Что входит в число смертей? 1 января 2023 г. CDC штата Мэн изменил свое определение смертности от COVID, чтобы оно соответствовало новым стандартам, установленным Советом государственных и территориальных эпидемиологов (CSTE) и CDC США.